Have you ever hurt yourself from your own code?
Nikita Skobov - April 25, 2021
Have you ever accidentally caused harm to yourself or others from your code? I have.
About a year ago I had several thousand WAV audio files that I generated. I was going through them and trying to label/categorize them into folders, creating metadata, etc. While doing so, I listened to a few of them, and to my dismay there was quite a bit of silence in the beginning. This is very annoying especially when you are listening to many audio files in a row and there is a long pause before the next one starts playing. Great. Even more work for me.
I spent some time looking into different ways of removing silence from audio files, until I remembered something: these were WAV files! A WAV file's data is usually raw PCM audio [1], meaning every "value" in the file represents the amplitude at that point in time. This would suggest if we have true silence, and not just white noise, then this silence should be all zeros, right?
$ xxd testfile1.wav | head -n 100
00000000: 5249 4646 64b9 0e00 5741 5645 666d 7420 RIFFd...WAVEfmt
00000010: 1000 0000 0100 0200 44ac 0000 10b1 0200 ........D.......
00000020: 0400 1000 6461 7461 40b9 0e00 0000 0000 ....data@.......
00000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000050: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000060: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000070: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000080: 0000 0000 0000 0000 0000 0000 0000 0000 ................
# ... and a lot more zeros below
Sure enough, it is. Well this might be easier than I thought. I could just read every file, find where the massive block of zeros ends, and then just remove that section.
How to read WAV files
First, I would need to learn a bit more about WAV files in order to parse them and manipulate the data. I found several references out there, but one of the better ones was an old page from stanford.edu (now gone, but luckily the wayback machine had it) that had a very nice diagram[2]:

So it seems that the WAV file format is quite simple. It just has a header of 44 bytes followed by the "data". At this point I was ready to start coding. I would just skip the first 44 bytes, remove all of the consecutive zeros in the beginning of the data section, and output the rest as is. Although I will admit that I also saw from another reference[3] that
Some programs (naively) assume that for PCM data, the preamble in the file header is exactly 44 bytes long (as in the table above) and that the rest of the file contains sound data. This is not a safe assumption.
Well this was fine by me because I was going to write this program in C, so I didn't really care about safety.
The code
The code was really simple — less than a hundred lines. It basically iterated over the file one byte at a time, skipping the first 44 bytes, and counting the number of consecutive zeros. Once it hit a non-zero it would stop reading the file, save that index, and then start reading the file again from the beginning. This time it would output the bytes one by one to standard output, and it would skip the bytes up to the index (except the header).
The full code is unnecessary, but the relevant part is here:
// index was calculated above to be the index of
// the last consecutive zero byte
FILE *f = fopen(argv[1], "rb");
int ind = 0;
int current_byte;
while ((current_byte = fgetc(f)) != EOF) {
if (ind < 44 || ind >= index) {
fputc(current_byte, stdout);
}
ind += 1;
}
fclose(f);
Great. simple enough. Time to test it. I ran the program on one of the files that had a lot of silence:
./strip_audio testfile1.wav > testfile1.nosilence.wav
I checked the output of xxd on testfile1.nosilence.wav. Awesome, no zeros in the beginning. It must have worked fine. For the final test, let's play it on my media player real quick.[4]
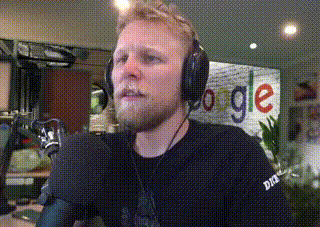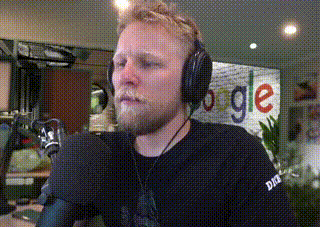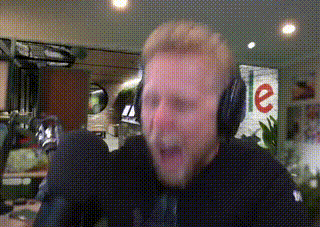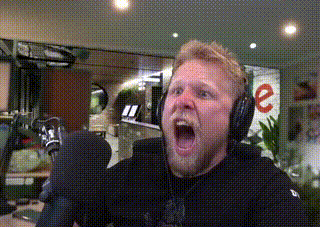
Immediately I was attacked by the loudest static noise I've ever heard. I scrambled to pull out my headset as I was falling back out of my chair. This was in the middle of the night and I remember my dog running over to check if I was ok.
What were my mistakes?
While my ears were still ringing, I started to reflect on my poor choices.
- Mistake #1: Should not have had my volume that loud.
- Mistake #2: Should not have had my headphones on
- Mistake #3: Off-by-one error:
Can you spot mistake #3 from the code above? Hint: the comment might help. I calculated the index variable as the index of the last zero byte. So now, other than the 44 byte header, we are only outputting bytes on or after the index. Since the index is on the last zero byte, then that means we are including an extra zero byte in the beginning of the data section.
We can fix this by changing the condition to be:
// replaced >= with just >
if (ind < 44 || ind > index) {
fputc(current_byte, stdout);
}
Now we are not outputting that extra zero, and if we test it again, the audio sounds fine. I fixed my bug...
But wait, if WAV files have raw PCM audio, and zeros mean silence in raw audio, wouldn't that extra zero just be silence? Why did it sound so loud and static-y?
First, let's look at a comparison using audacity of the good and the evil audio files I made:
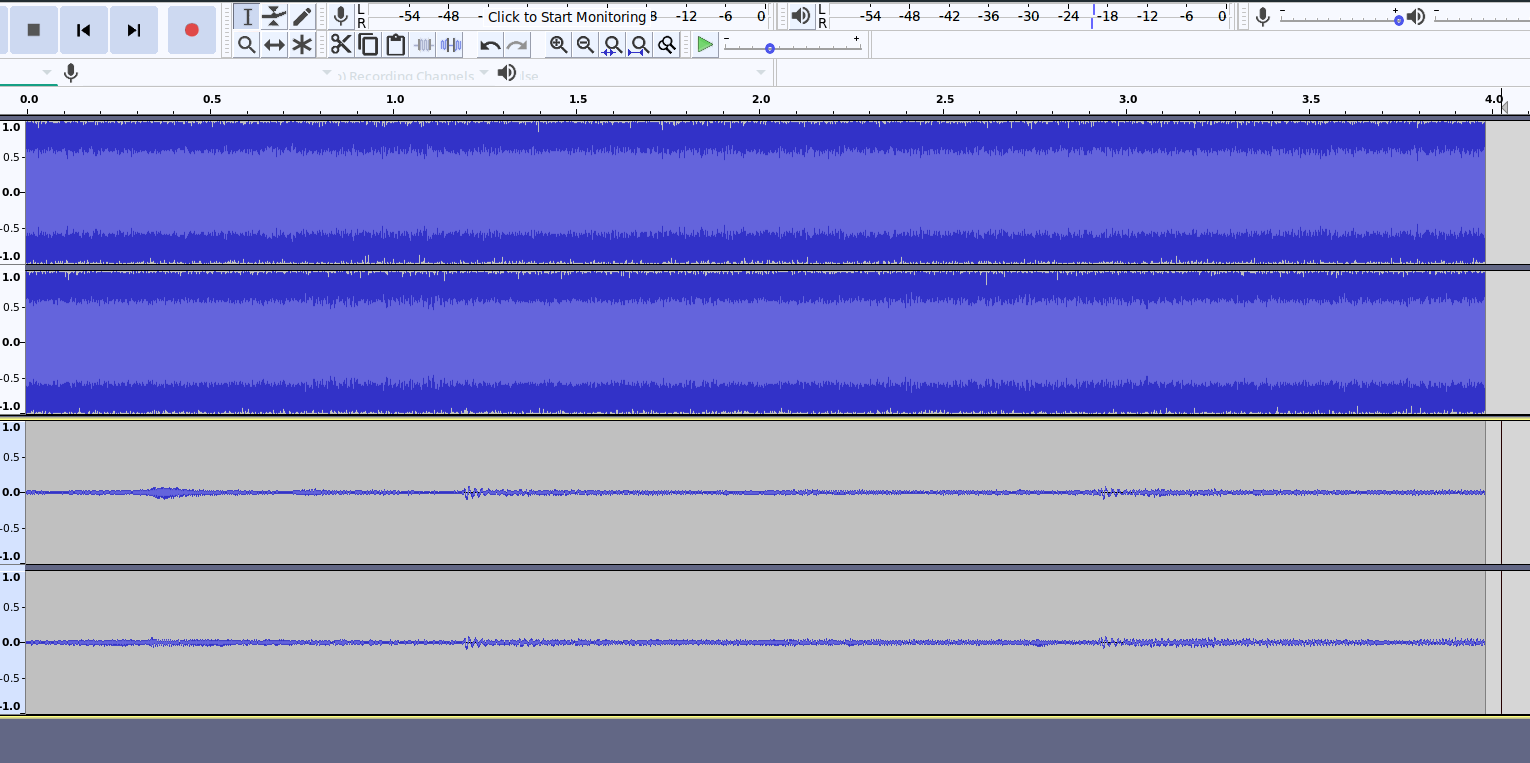
Can you guess which one is the evil file? Yep, it's the one that is nearly at max amplitude the whole time. What gives?
How audio samples are read
Looking back at some of the references I found earlier, I tried to figure out why an off-by-one error could cause the amplitude to explode like that. I know that my audio file has 16 bits per sample, and 2 channels (stereo), so I searched for that and under a section for 16-bit stereo PCM I found [5]:
Each sample is contained in an integer i. The size of i is the smallest number of bytes required to contain the specified sample size. The least significant byte is stored first.
"The size of i is the smallest number of bytes" is unnecessarily confusing. i is the bits per sample. in our case that's 16. This means that we have some value that is 16 bits long, and we are of course storing it over 2 bytes. The next part is important: The least significant byte is stored first.
Yep, that's it.
Let's look at a graphic I made showing what was causing this really high waveform seen above:
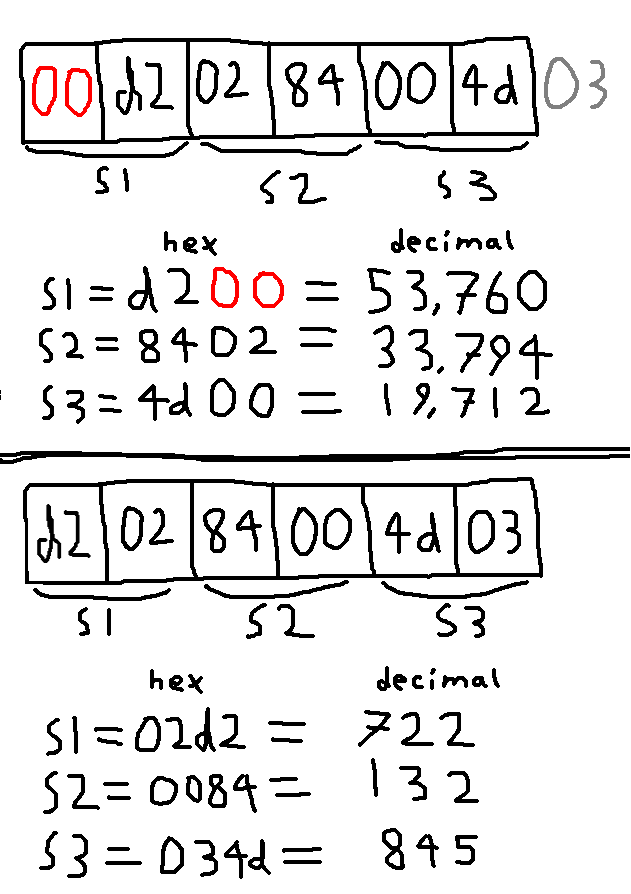
The top part shows my evil file where I accidentally had an extra zero byte in the beginning. The three samples, s1, s2, and s3, each have two bytes, where the second byte is the most significant byte. Therefore, when converting these byte pairs to decimal, we see really high amplitudes for these three samples.
However, in the bottom section we see that if I remove that extra zero byte, the samples are read as they should be, and have much more reasonable values for an audio file.
So If my audio file had 8 bits per sample, then inserting an extra byte would not have been a problem. However, because it was 16 bits per sample, I was essentially shifting all of the samples, and causing the least significant byte to be read as the most significant byte.
Conclusion
- Look at an audio file's waveform before playing it at max volume.
- Read (and follow) the specification.
- Think about the consequences your code could have on you or others.
References
[1]
[2]
[3]
[4]
[5]
About me:
I am Nikita Skobov.
Contact me via email: skobo002@umn.edu.
Check out my projects: https://github.com/nikita-skobov.
Check out my other blog posts: https://blog.nikitas.link.